

Uno de los principales problemas de rendimiento de las Bases de Datos Relacionales Transaccionales (OLTP) se produce al incluir Cargas de Trabajo Analíticas (OLAP) con consultas que recuperan gran cantidad de información. En muchos casos para fines ajenos a la propia aplicación como los sistemas BI. Este tipo de acceso tiene un impacto considerable en el rendimiento por varias razones, como la capacidad de la infraestructura de base de datos adaptada al uso transaccional de la aplicación, o el diseño del modelo de datos optimizado para el tipo de acceso, más atómico, de un sistema transaccional que analítico.
Para resolver estos problemas Amazon Aurora dispone de dos funcionalidades que vamos a estudiar, Auto Scaling de réplicas de sólo lectura (Readers) y Custom Endpoints dedicados a instancias específicas.
En este post de la serie de dos partes vamos a explorar las capacidades de Auto Scaling de Amazon Aurora, cómo funciona, cómo aprovechar las capacidades de failover, cómo implementarlo y algunos consejos perspicaces para sacarle el máximo partido. Comencemos.
Readers Auto Scaling#
Amazon Aurora Auto Scaling permite ajustar automáticamente el número de réplicas de lectura de un clúster de Amazon Aurora RDS. Esto le permite principalmente ajustar la capacidad de la plataforma para cargas de trabajo impredecibles.
Amazon Aurora Auto Scaling permite definir un máximo y un mínimo de instancias del mismo modo que los grupos de Amazon EC2 Auto Scaling. Sin embargo, como diferencia, en lugar de definir un valor de escalado de salida y un valor de escalado de entrada para la métrica de Auto Scaling, solo se define un valor objetivo, que sirve como valor de umbral superior. Amazon Aurora Auto Scaling define automáticamente el valor inferior
Funcionamiento#
El funcionamiento de Amazon Aurora Auto Scaling se basa en dos componentes diferentes que es necesario definir.
Scalable target#
Se encarga de definir la capacidad máxima y mínima del autoescalado. Solo puede existir un scalable target por clúster de Amazon Aurora. La capacidad definida en el objetivo escalable afecta a todo, es decir, se tiene en cuenta el número total de instancias de tipo Reader ya sean autogestionadas o gestionadas por autoescalado.
Algunos ejemplos:
Supongamos que tenemos la siguiente capacidad.
Min capacity: 1
Max capacity: 4
El clúster mostrado a continuación tendría la capacidad de crecer sólo 2 instancias más ya que el número total de instancias Reader no puede superar las 4 unidades. De la misma forma no se puede tener menos de 1 instancia Reader, sin embargo, cuando se tiene una instancia Reader autogestionada, se podría llegar a tener 0 instancias Reader gestionadas por Auto Scaling.
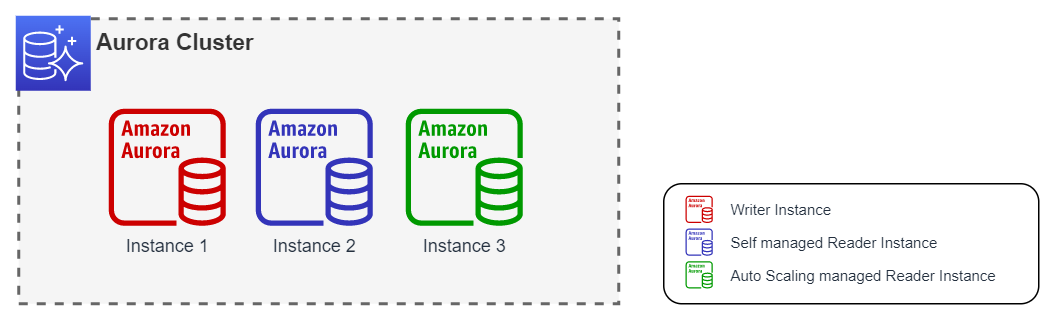
En el siguiente caso, el clúster tendría la capacidad de aumentar 1 instancia más hasta alcanzar el máximo. Para el mínimo, podría eliminar todas las instancias de lectura excepto 1.
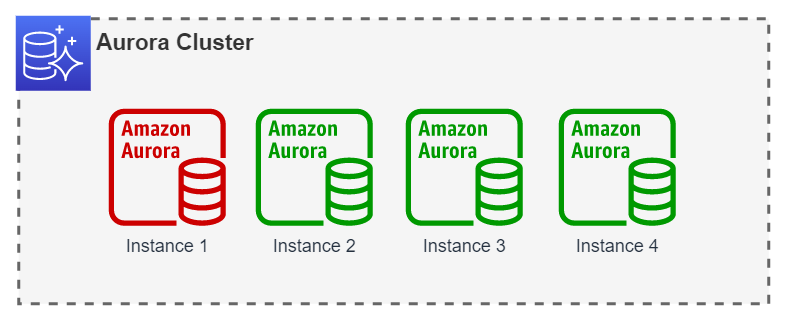
En este último ejemplo, ya se ha alcanzado la capacidad máxima de Auto Scaling, de hecho, se ha superado al tener 5 instancias autogestionadas ya creadas. El límite de Auto Scaling no influye en el límite máximo de instancias Reader autogestionadas en un clúster de Amazon Aurora, sin embargo el límite máximo permitido por Amazon Aurora es de 15. Este límite incluye ambos tipos de instancias Reader, autogestionadas o gestionadas por Auto Scaling.
Scaling-policy#
Se encarga de definir la métrica a monitorizar para controlar el Auto Escalado, y el valor objetivo a alcanzar en el clúster.
Puede haber varias políticas de escalado asociadas a un objetivo de escalado, aunque lo habitual es definir sólo una.
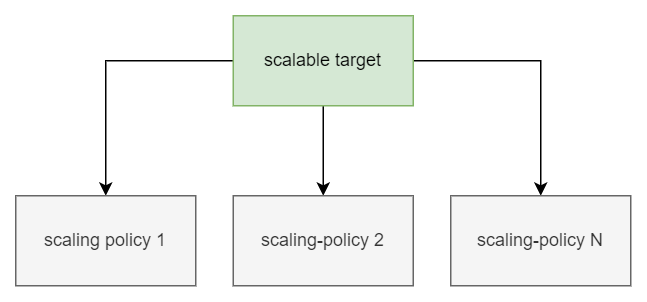
Las métricas pueden ser de dos tipos, predefinidas o personalizadas.
Las métricas predefinidas que puede elegir son dos:
RDSReaderAverageCPUUtilization: Es el valor medio de la métrica CPUUtilization en CloudWatch entre todas las réplicas de Aurora en el clúster de Amazon Aurora.
RDSReaderAverageDatabaseConnections: Es el valor medio de la métrica DatabaseConnections en CloudWatch entre todas las réplicas de Aurora en el clúster de Aurora.
Para las métricas personalizadas se puede elegir cualquier métrica que tenga sentido, siempre y cuando se tenga en cuenta el estado de todas las réplicas de lectura. Una limitación de esto es, por ejemplo, la imposibilidad de elegir una métrica que afecte sólo a un subconjunto de instancias de réplica de lectura. Esto se debe a cómo están organizadas las dimensiones en CloudWatch para RDS/Aurora. En un clúster de Amazon Aurora, las únicas dimensiones válidas son ClusterId, Role (Writer o Reader) o sólo ClusterId.
Failover del cluster Auto Scaling#
Para evitar el failover en una instancia administrada de Auto Scaling, AWS asigna la prioridad más baja (tier-15) a este tipo de instancia. De este modo, las instancias Reader autogestionadas (normalmente con prioridad de nivel 1) tendrán preferencia como candidatas en caso de failover. Sin embargo, si no hay Readers autogestionados en el clúster, cualquiera de las instancias Reader autogestionadas de Auto Scaling se marcaría como candidata en caso de failover.
Algunos ejemplos:
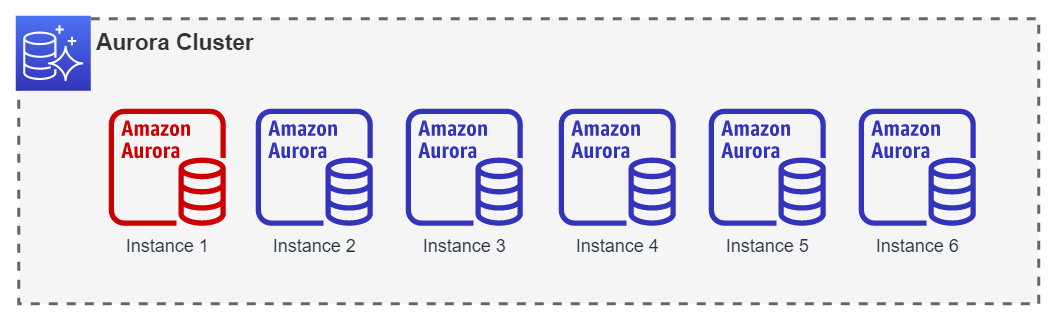
En este caso, el failover se realizará siempre entre la instancia 1 y la instancia 2.
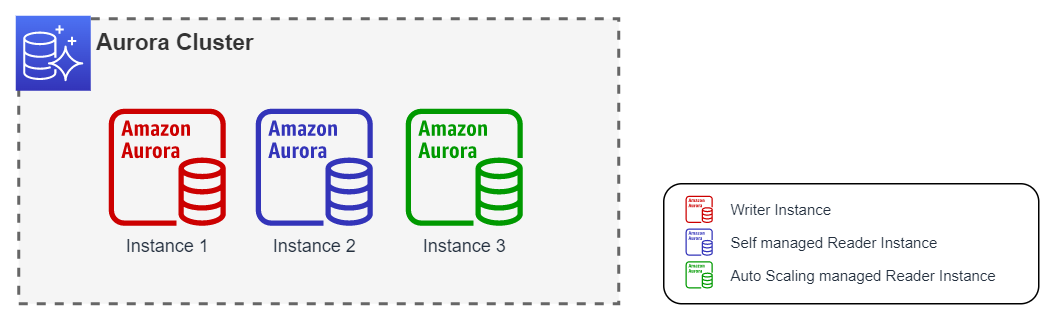
En este caso, el failover se realizará a cualquiera de las instancias Reader (2, 3 o 4), sin embargo, un segundo failover siempre volverá a la instancia 1.
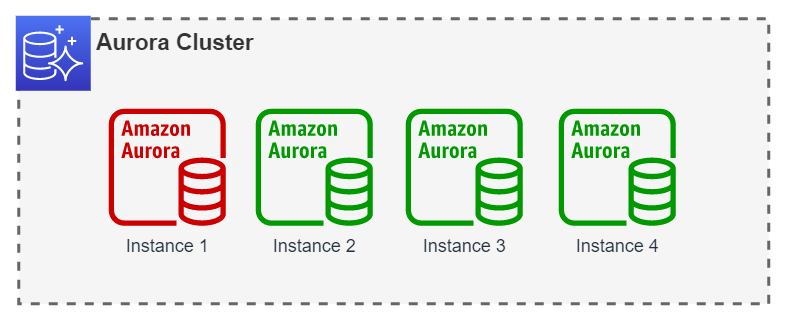
Implementación#
Se puede implementar la configuración de Auto Scale tanto desde la consola de AWS como desde la CLI de AWS. Desde la consola de AWS sólo es posible utilizar métricas predefinidas. La creación tanto del objetivo escalable como de la política de escalado se realiza en un único paso, por lo que resulta muy sencillo de configurar.
Desde AWS CLI, es necesario definir el objetivo escalable y la política de escalado individualmente, también es necesario definir la configuración de la métrica en un JSON que se utiliza como entrada en la creación de la política de escalado. Esto se aplica tanto si la métrica está predefinida como si es personalizada.
Los detalles de implementación se pueden encontrar en Using Amazon Aurora Auto Scaling with Aurora replicas.
Limitaciones y recomendaciones#
Aunque algunas de las limitaciones ya se han comentado en secciones anteriores, es necesario tener en cuenta las siguientes limitaciones y recomendaciones de Amazon Aurora Autoscaling.
No configure Capacidad mínima = 0, especialmente en aquellos clusters que no dispongan de instancias Reader autogestionadas. Si un clúster se queda sin instancias Reader, el Auto Scaling deja de funcionar, ya que las reglas que ejecutan el escalado se quedan en estado de Datos insuficientes.
Si todas las instancias del clúster no están en estado Disponible, las acciones de Autoescalado no se ejecutan.
El valor objetivo de la métrica define el límite máximo del Auto Scale, es decir, aquel que una vez superado provoca un scale-out. El valor mínimo es auto calculado por AWS y es siempre un 10% inferior al valor máximo. Cuando la métrica está por debajo de este valor mínimo se produce un scale-in.
El periodo de tiempo que la métrica tiene que estar por encima o por debajo del valor máximo o mínimo respectivamente es fijo. El valor máximo es de 5 minutos. El valor mínimo es de 15 minutos.
El incremento de instancias en el scale-out es variable, AWS determina el número de instancias necesarias para alcanzar el valor objetivo, siempre dentro de los límites máximo y mínimo, y las crea al mismo tiempo.
El decremento de instancias en el scale-in es siempre fijo con un ritmo de 1 instancia cada vez.
Si no hay instancias autogestionadas Reader, la conmutación por error del clúster se realiza en una de las instancias gestionadas por Auto Scaling.
Custom Endpoints#
En un clúster de Amazon Aurora, el uso de endpoints permite asignar cada conexión con un conjunto de instancias. De forma predeterminada, cada clúster de Amazon Aurora incluye 2 endpoints predefinidos.
Writer Endpoint: Apunta a la instancia que actualmente tiene el rol Writer en el clúster.
Reader Endpoint: Apunta a la instancia o instancias que actualmente tienen el rol Reader en el clúster.
Además, AWS permite la creación de endpoints personalizados en los que puede especificar un conjunto discreto de instancias para incluir.
Cómo funciona#
Los endpoints personalizados pueden ser de tres tipos. READER, WRITER o ANY. Cada tipo solo puede contener instancias que tengan el rol correspondiente.
Es importante saber que cuando se producen cambios en la configuración de los endpoints personalizados, las conexiones activas en las instancias no se interrumpen ni alteran. Por lo tanto, los cambios que se producen en un endpint, por ejemplo cuando se agrega o elimina una instancia, solo tienen efecto en las nuevas conexiones que se realizan desde ese momento.
Un endpoint personalizado puede definirse mediante una lista de inclusión o una lista de exclusión. Solo puede tener un tipo de lista para cada endpoint personalizado. Las instancias incluidas en dichas listas se incluyen o excluyen del endpint independientemente de si el rol de la instancia coincide con el tipo del endpoint personalizado.
Cuando se define una lista de inclusión (lista blanca), solo se incluyen en el endpoint las instancias indicadas en ella. Cualquier nueva instancia creada desde entonces también permanecerá fuera del endpoint.
Sin embargo, para las listas de exclusión (lista negra) solo aquellas instancias incluidas en la lista serán excluidas del endpoint. Cualquier otra instancia no especificada, así como las instancias que se crean a partir de ese momento se incluirán en el endpoint.
Para obtener más información sobre el uso de endpoints personalizados, consulte Amazon Aurora connection management.
Uso simultáneo de Readers Auto Scaling y Custom Endpoints#
Como podemos ver en la sección sobre Readers Auto Scaling, aunque a través de endpoints personalizados es posible crear un subconjunto de instancias de lectura a las que se accede solo para un propósito específico y, de esta manera, no afectan al resto de instancias del clúster, no es posible configurar métricas de escalado automático que midan solo un subconjunto de instancias. Estas métricas siempre medirán todas las instancias con un rol READER. Cualquier acceso masivo a solo una de las instancias tendrá un efecto en el promedio de todo el conjunto y, por lo tanto, influirá en el escalado del clúster.
Por lo tanto, la conclusión final es que el uso de ambas tecnologías combinadas no permite resolver el problema que se ha planteado inicialmente.
Configuración recomendada#
En base a lo visto en los apartados anteriores, se recomienda la siguiente configuración estándar. Será necesario adaptarla a las necesidades específicas del clúster de Amazon Aurora en el que se vaya a aplicar.
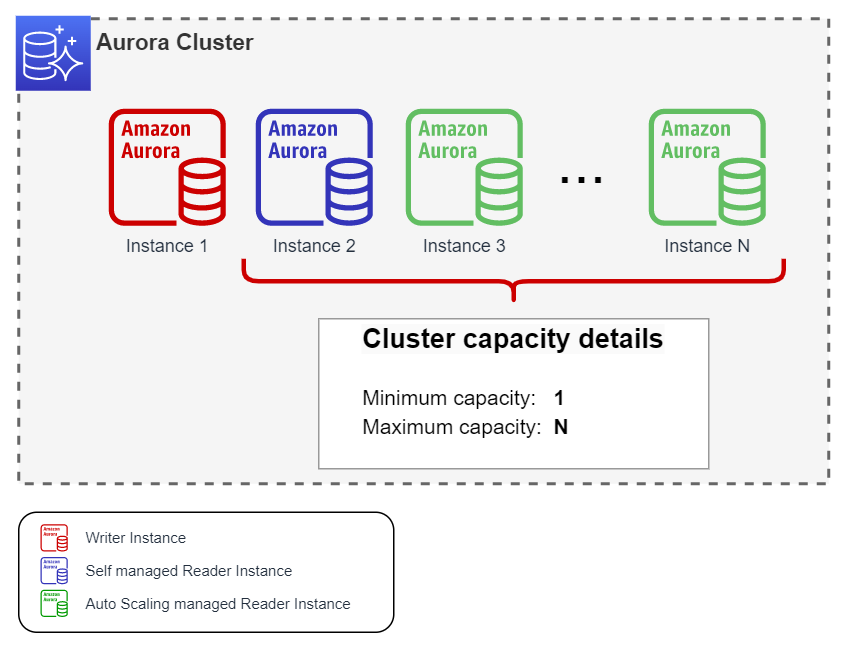
Como regla general para esta configuración, se recomienda tener una instancia Writer y una instancia Reader autogestionada del mismo tipo y tamaño. Se recomienda dejar el parámetro Failover priority en su valor por defecto que es tier-1, asegurando así que el failover del clúster se realizará siempre entre estas dos instancias. El número de instancias gestionadas por Auto Scaling será variable, entre cero y el número máximo que se especifique en la configuración dependiendo de la carga de lectura en el clúster.
Se recomienda aplicar la configuración en la consola de AWS, aunque también es posible hacerlo en AWS CLI tal y como se describe en Adding a scaling policy to an Aurora DB cluster.
Estos son los parámetros recomendados:
Detalles de la política#
Target metric: Se recomienda elegir cualquiera de las métricas predefinidas en función de las necesidades del clúster. Estas son Average CPU utilization of Aurora Replicas o Average connections of Aurora Replicas.
Target value: El valor objetivo a mantener para la Target metric seleccionada.
Detalles de la capacidad del cluster#
Minimum capacity: Se recomienda utilizar siempre el valor 1.
Maximum capacity: Indique el número máximo de instancias deseadas según las necesidades del clúster. El límite máximo es 15.
Conclusión#
En conclusión, este artículo destaca los retos de rendimiento de integrar cargas de trabajo analíticas con bases de datos relacionales transaccionales e introduce las características clave de Amazon Aurora: Auto Scaling de réplicas de solo lectura y Custom Endpoints. Se ha visto en detalle Amazon Aurora Auto Scaling, incluidas las estrategias de failover y sus limitaciones. El artículo también ha explorado los Custom Endpoints y sus tipos. Sin embargo, el uso simultáneo de Readers Auto Scaling y Custom Endpoints resulta insuficiente para abordar plenamente los desafíos de integrar las cargas de trabajo de OLAP con las bases de datos OLTP.
Si has encontrado útil este artículo, suscríbete a la newsletter y recibe directamente en tu bandeja de entrada artículos, guías y novedades sobre AWS.
SuscríbeteReferences#
Using Amazon Aurora Auto Scaling with Aurora replicas